[TOC]
RabbitMQ 即一个消息队列,主要是用来实现应用程序的异步和解耦,同时也能起到消息缓冲,消息分发的作用。
消息中间件最主要的作用是解耦,中间件最标准的用法是生产者生产消息传送到队列,消费者从队列中拿取消息并处理,生产者不用关心是谁来消费,消费者不用关心谁在生产消息,从而达到解耦的目的。在分布式的系统中,消息队列也会被用在很多其它的方面,比如:分布式事务的支持,RPC 的调用等等。
RabbitMQ介绍
RabbitMQ 是一个开源的 AMQP 实现,服务器端用Erlang语言编写,支持多种客户端,如:Python、Ruby、.NET、Java、JMS、C、PHP、ActionScript、XMPP、STOMP 等,支持 AJAX。用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。
RabbitMQ 是实现 AMQP(高级消息队列协议)的消息中间件的一种,最初起源于金融系统,用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。
RabbitMQ 是一种典型的点对点模式,消息被消费以后,队列中不会再存储,所以消息消费者不可能消费到已经被消费的消息。虽然队列可以支持多个消费者,但是一条消息只会被一个消费者消费。 RabbitMQ 中可以通过设置交换器类型来实现发布订阅模式而达到广播消费的效果。
AMQP
AMQP,即 Advanced Message Queuing Protocol,高级消息队列协议(是一个进程间传递异步消息的网络协议。),是应用层协议的一个开放标准,为面向消息的中间件设计。消息中间件主要用于组件之间的解耦,消息的发送者无需知道消息使用者的存在,反之亦然。AMQP 的主要特征是面向消息、队列、路由(包括点对点和发布/订阅)、可靠性、安全。
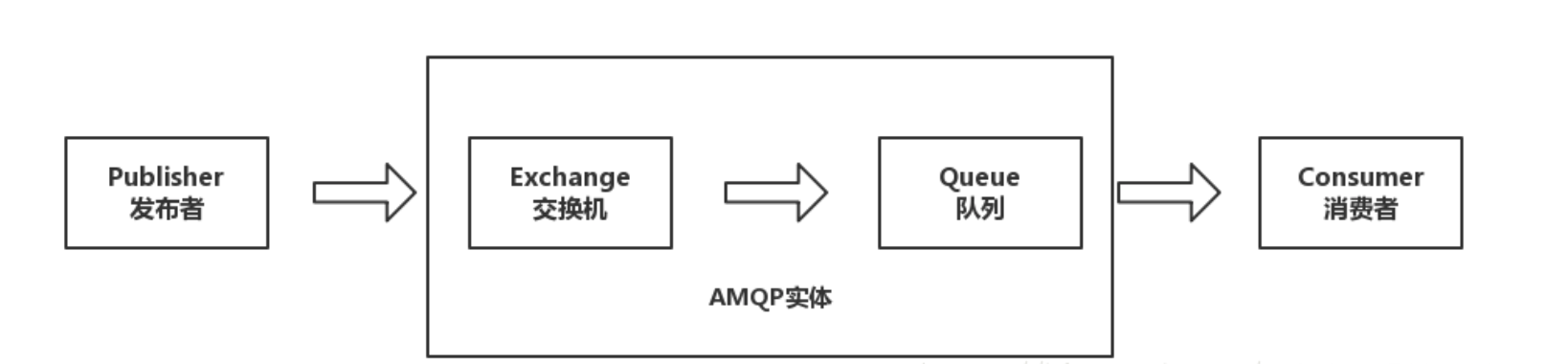
工作过程
发布者(Publisher)发布消息(Message),经由交换机(Exchange)。
交换机根据路由规则将收到的消息分发给与该交换机绑定的队列(Queue)。
最后 AMQP 代理会将消息投递给订阅了此队列的消费者,或者消费者按照需求自行获取。
相关概念
通常我们谈到队列服务, 会有三个概念: 发消息者、队列、收消息者,RabbitMQ 在这个基本概念之上, 多做了一层抽象, 在发消息者和 队列之间, 加入了交换器 (Exchange). 这样发消息者和队列就没有直接联系, 转而变成发消息者把消息给交换器, 交换器根据调度策略再把消息再给队列。
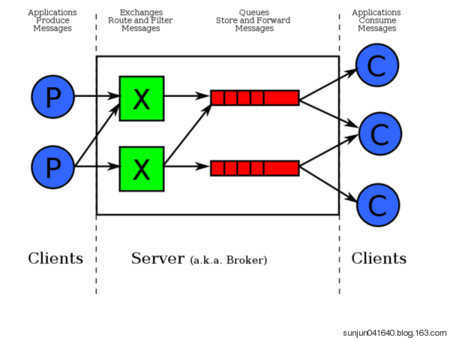
- 左侧 P 代表 生产者,也就是往 RabbitMQ 发消息的程序。
- 中间即是 RabbitMQ,其中包括了 交换机 和 队列。
- 右侧 C 代表 消费者,也就是往 RabbitMQ 拿消息的程序。
broker
接收和分发消息的应用,RabbitMQ Server就是消息代理服务器
exchange
消息到达代理服务器的第一站,根据分发规则,匹配查询表中的(routing key)路由键分发消息到队列(queue)中去。
共有4种类型:direct,topic,headers和fanout。
binding key
一个绑定就是基于路由键将交换机和队列连接起来的路由规则,所以交换机不过就是一个由绑定构成的路由表。
queue
消息最终到达队列中,等待消费者消费。
原理介绍
RabbitMQ这款消息队列中间件产品本身是基于Erlang编写,Erlang语言天生具备分布式特性(通过同步Erlang集群各节点的magic cookie来实现)。因此,RabbitMQ天然支持Clustering。这使得RabbitMQ本身不需要像ActiveMQ、Kafka那样通过ZooKeeper分别来实现HA方案和保存集群的元数据。集群是保证可靠性的一种方式,同时可以通过水平扩展以达到增加消息吞吐量能力的目的。 下面先来看下RabbitMQ集群的整体方案:
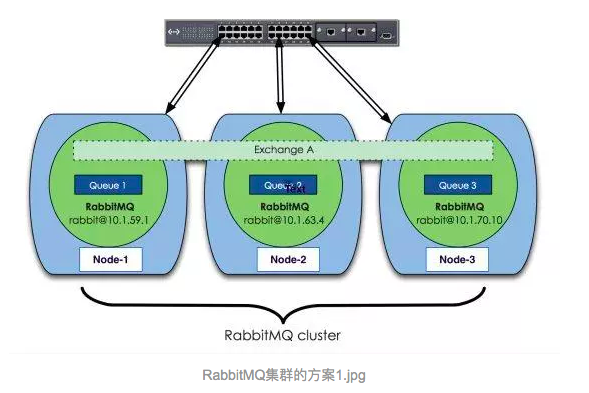
上面图中采用三个节点组成了一个RabbitMQ的集群,Exchange A(交换器,对于RabbitMQ基础概念不太明白的童鞋可以看下基础概念)的元数据信息在所有节点上是一致的,而Queue(存放消息的队列)的完整数据则只会存在于它所创建的那个节点上。,其他节点只知道这个queue的metadata信息和一个指向queue的owner node的指针。
数据同步
RabbitMQ集群数据的同步,仅同步元数据
RabbitMQ集群会始终同步四种类型的内部元数据:
a. 队列元数据:队列名称和它的属性
b. 交换器元数据:交换器名称、类型和属性
c. 绑定元数据:一张简单的表格展示了如何将消息路由到队列
d. vhost元数据:为vhost内的队列、交换器和绑定提供命名空间和安全属性
rabbitmq 集群部署
erlang安装
# 三台机器
10.21.8.63 host63
10.21.8.64 host64
10.21.8.65 host65
# cat /etc/yum.repos.d/rabbitmq_erlang.repo
[rabbitmq_erlang]
name=rabbitmq_erlang
baseurl=https://packagecloud.io/rabbitmq/erlang/el/7/$basearch
repo_gpgcheck=1
gpgcheck=0
enabled=1
gpgkey=https://packagecloud.io/rabbitmq/erlang/gpgkey
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt
metadata_expire=300
[rabbitmq_erlang-source]
name=rabbitmq_erlang-source
baseurl=https://packagecloud.io/rabbitmq/erlang/el/7/SRPMS
repo_gpgcheck=1
gpgcheck=0
enabled=1
gpgkey=https://packagecloud.io/rabbitmq/erlang/gpgkey
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt
metadata_expire=300
yum install erlang
rabbitmq安装
yum install socat -y
wget https://github.com/rabbitmq/rabbitmq-server/releases/download/v3.7.14/rabbitmq-server-3.7.14-1.el7.noarch.rpm
rpm -ivh rabbitmq-server-3.7.14-1.el7.noarch.rpm
#先启动63,将.erlang.cookie复制到其他两个节点,再启动其他节点 节点之间通过cookie通信。
rabbitmq-server -detached
rabbitmqctl status
rabbitmqctl cluster_status
# 集群模式保证所有机器`/var/lib/rabbitmq/.erlang.cookie`文件都一致。
chown rabbitmq:rabbitmq /var/lib/rabbitmq/.erlang.cookie
chmod 400 /var/lib/rabbitmq/.erlang.cookie
# 以63为主节点 64 65上执行
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster rabbit@host63
rabbitmqctl start_app
#63上查看
# rabbitmqctl cluster_status
Cluster status of node rabbit@host63 ...
[{nodes,[{disc,[rabbit@host63,rabbit@host64,
rabbit@host65]}]},
{running_nodes,[rabbit@host65,rabbit@host64,
rabbit@host63]},
{cluster_name,<<"rabbit@host63.cdn.idc.com">>},
{partitions,[]},
{alarms,[{rabbit@host65,[]},
{rabbit@host64,[]},
{rabbit@host63,[]}]}]
内存|磁盘节点
在RabbitMQ集群中的节点只有两种类型:内存节点/磁盘节点,单节点系统只运行磁盘类型的节点。而在集群中,可以选择配置部分节点为内存节点。 内存节点将所有的队列,交换器,绑定关系,用户,权限,和vhost的元数据信息保存在内存中。而磁盘节点将这些信息保存在磁盘中,但是内存节点的性能更高,为了保证集群的高可用性,必须保证集群中有两个以上的磁盘节点,来保证当有一个磁盘节点崩溃了,集群还能对外提供访问服务。在上面的操作中,可以通过如下的方式,设置新加入的节点为内存节点还是磁盘节点:
#加入时候设置节点为内存节点(默认加入的为磁盘节点)
[root@mq-testvm1 ~]# rabbitmqctl join_cluster rabbit@rmq-broker-test-1 --ram
#也通过下面方式修改的节点的类型
[root@mq-testvm1 ~]# rabbitmqctl changeclusternode_type disc | ram
haproxy配置
global
log 127.0.0.1 local2
chroot /usr/share/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
# turn on stats unix socket
# stats socket /var/lib/haproxy/stats
#---------------------------------------------------------------------
# common defaults that all the 'listen' and 'backend' sections will
# use if not designated in their block
#---------------------------------------------------------------------
defaults
mode http
log global
option httplog
option dontlognull
#option http-server-close
#option forwardfor except 127.0.0.0/8
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
listen stats
bind 0.0.0.0:1080
mode http
maxconn 5000
stats refresh 30s
stats uri /stats
listen rabbitmq_cluster
bind 0.0.0.0:5672
#配置TCP模式
mode tcp
option tcplog
#加权轮询
balance roundrobin
#RabbitMQ集群节点配置,其中ip1~ip7为RabbitMQ集群节点ip地址
server rmq_node1 10.21.8.63:5672 check inter 5000 rise 2 fall 3 weight 1
server rmq_node2 10.21.8.64:5672 check inter 5000 rise 2 fall 3 weight 1
server rmq_node3 10.21.8.65:5672 check inter 5000 rise 2 fall 3 weight 1
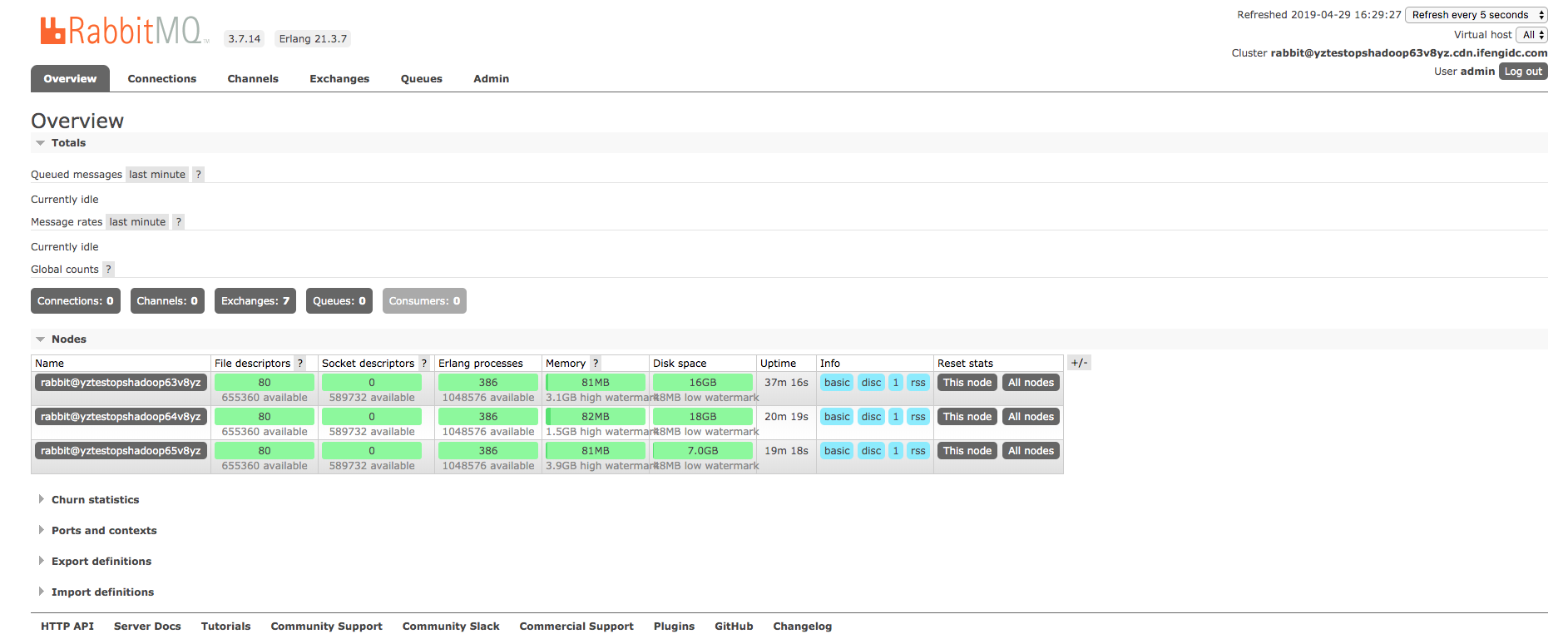
rabbitmq_management
rabbitmq-plugins enable rabbitmq_management
rabbitmqctl list_users
rabbitmqctl add_user admin admin123
rabbitmqctl set_user_tags admin administrator
rabbitmqctl cluster_status
rabbitmqctl forget_cluster_node rabbit@node1 # 移除节点