[TOC]
Prometheus的基本架构
Prometheus是一个开源的完整监控解决方案,涵盖数据采集、查询、告警、展示整个监控流程,下图是Prometheus的架构图:
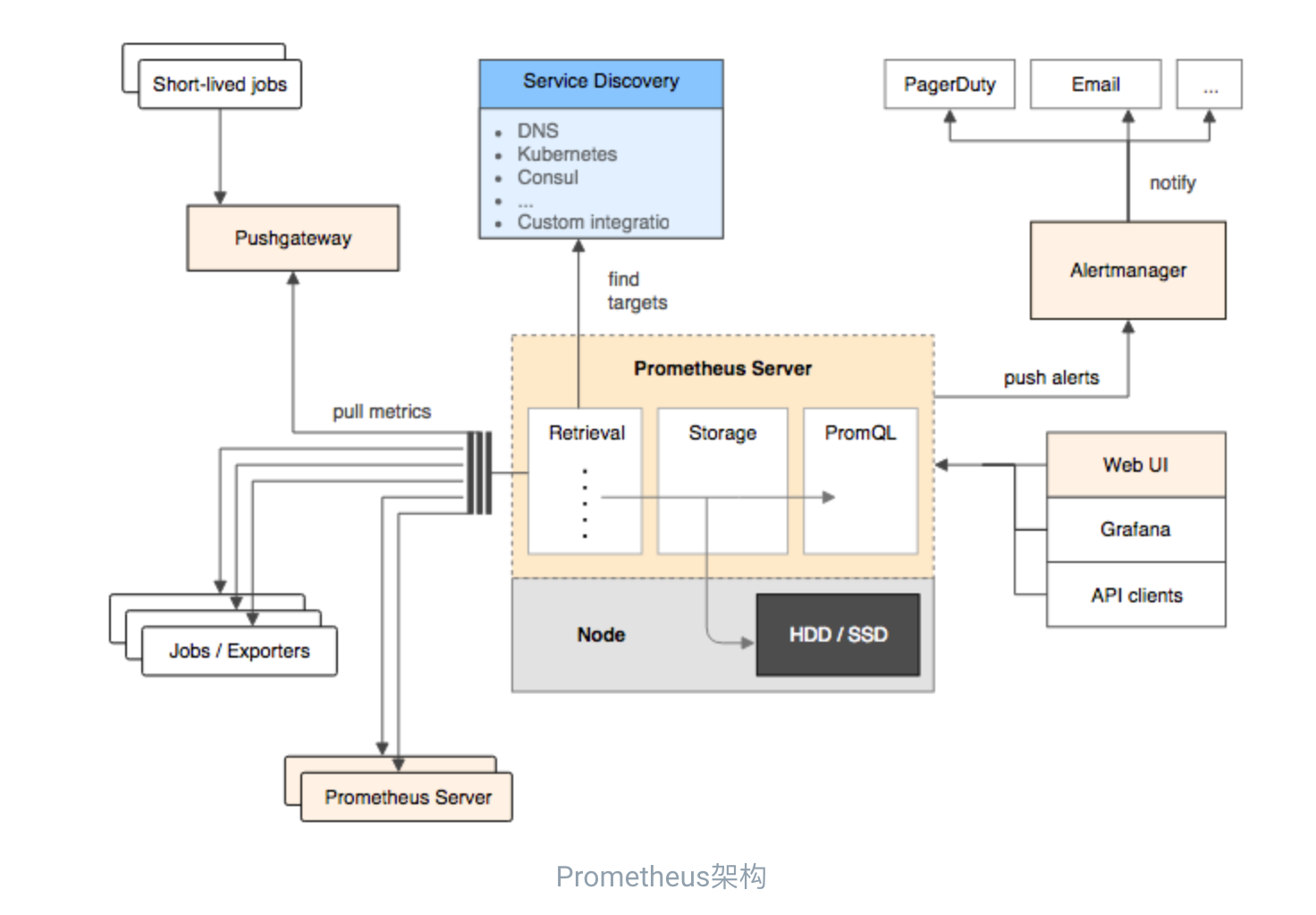
Prometheus Server
Prometheus Server是Prometheus组件中的核心部分,负责实现对监控数据的获取,存储以及查询。 Prometheus Server可以通过静态配置管理监控目标,也可以配合使用Service Discovery的方式动态管理监控目标,并从这些监控目标中获取数据。其次Prometheus Server需要对采集到的监控数据进行存储,Prometheus Server本身就是一个时序数据库,将采集到的监控数据按照时间序列的方式存储在本地磁盘当中。最后Prometheus Server对外提供了自定义的PromQL语言,实现对数据的查询以及分析。
Prometheus Server内置的Express Browser UI,通过这个UI可以直接通过PromQL实现数据的查询以及可视化。
Prometheus Server的联邦集群能力可以使其从其他的Prometheus Server实例中获取数据,因此在大规模监控的情况下,可以通过联邦集群以及功能分区的方式对Prometheus Server进行扩展。
Exporters
Exporter将监控数据采集的端点通过HTTP服务的形式暴露给Prometheus Server,Prometheus Server通过访问该Exporter提供的Endpoint端点,即可获取到需要采集的监控数据。
一般来说可以将Exporter分为2类:
- 直接采集:这一类Exporter直接内置了对Prometheus监控的支持,比如cAdvisor,Kubernetes,Etcd,Gokit等,都直接内置了用于向Prometheus暴露监控数据的端点。
- 间接采集:间接采集,原有监控目标并不直接支持Prometheus,因此我们需要通过Prometheus提供的Client Library编写该监控目标的监控采集程序。例如: Mysql Exporter,JMX Exporter,Consul Exporter等。
AlertManager
在Prometheus Server中支持基于PromQL创建告警规则,如果满足PromQL定义的规则,则会产生一条告警,而告警的后续处理流程则由AlertManager进行管理。在AlertManager中我们可以与邮件,Slack等等内置的通知方式进行集成,也可以通过Webhook自定义告警处理方式。AlertManager即Prometheus体系中的告警处理中心。
PushGateway
由于Prometheus数据采集基于Pull模型进行设计,因此在网络环境的配置上必须要让Prometheus Server能够直接与Exporter进行通信。 当这种网络需求无法直接满足时,就可以利用PushGateway来进行中转。可以通过PushGateway将内部网络的监控数据主动Push到Gateway当中。而Prometheus Server则可以采用同样Pull的方式从PushGateway中获取到监控数据。
prometheus配置文件
# Prometheus全局配置项
global:
scrape_interval: 15s # 设定抓取数据的周期,默认为1min
evaluation_interval: 15s # 设定更新rules文件的周期,默认为1min
scrape_timeout: 15s # 设定抓取数据的超时时间,默认为10s
external_labels: # 额外的属性,会添加到拉取得数据并存到数据库中
monitor: 'codelab_monitor'
# Alertmanager配置
alerting:
alertmanagers:
- static_configs:
- targets: ["localhost:9093"] # 设定alertmanager和prometheus交互的接口,即alertmanager监听的ip地址和端口
# rule配置,首次读取默认加载,之后根据evaluation_interval设定的周期加载
rule_files:
- "alertmanager_rules.yml"
- "prometheus_rules.yml"
# scape配置
scrape_configs:
- job_name: 'prometheus' # job_name默认写入timeseries的labels中,可以用于查询使用
scrape_interval: 15s # 抓取周期,默认采用global配置
static_configs: # 静态配置
- targets: ['localdns:9090'] # prometheus所要抓取数据的地址,即instance实例项
- job_name: 'example-random'
static_configs:
- targets: ['localhost:8080']
Prometheus报警
promethus的告警被分成两个部分:
- 通过在Prometheus中定义告警触发条件规则,并向Alertmanager发送告警信息
- Alertmanager作为一个独立的组件,负责接收并处理来自Prometheus的告警信息
在Prometheus全局配置文件中prometheus.yml通过rule_files指定一组告警规则文件的访问路径。Prometheus启动后会自动扫描这些路径下规则文件中定义的内容,并且根据这些规则计算是否向外部发送通知
Prometheus-Operator
架构
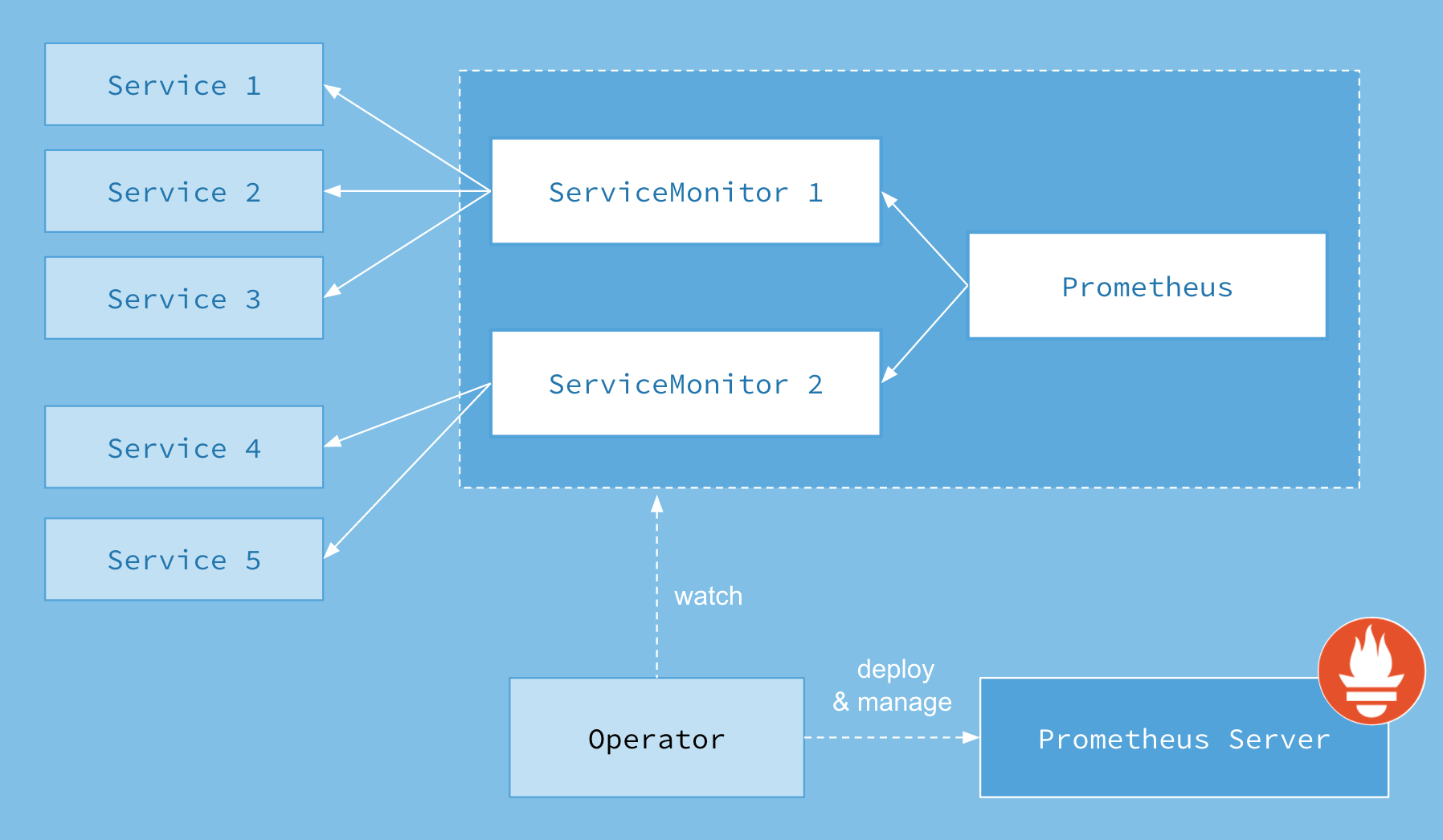
上图是Prometheus-Operator官方提供的架构图,其中Operator是最核心的部分,作为一个控制器,他会去创建Prometheus、ServiceMonitor、AlertManager以及PrometheusRule4个CRD资源对象,然后会一直监控并维持这4个资源对象的状态。
其中创建的prometheus这种资源对象就是作为Prometheus Server存在,而ServiceMonitor就是exporter的各种抽象,exporter前面我们已经学习了,是用来提供专门提供metrics数据接口的工具,Prometheus就是通过ServiceMonitor提供的metrics数据接口去 pull 数据的,当然alertmanager这种资源对象就是对应的AlertManager的抽象,而PrometheusRule是用来被Prometheus实例使用的报警规则文件。
这样我们要在集群中监控什么数据,就变成了直接去操作 Kubernetes 集群的资源对象了,是不是方便很多了。上图中的 Service 和 ServiceMonitor 都是 Kubernetes 的资源,一个 ServiceMonitor 可以通过 labelSelector 的方式去匹配一类 Service,Prometheus 也可以通过 labelSelector 去匹配多个ServiceMonitor。
CustomResourceDefinitions
The Operator acts on the following custom resource definitions (CRDs):
- Prometheus, which defines a desired Prometheus deployment. The Operator ensures at all times that a deployment matching the resource definition is running.
- ServiceMonitor, which declaratively specifies how groups of services should be monitored. The Operator automatically generates Prometheus scrape configuration based on the definition.
- PrometheusRule, which defines a desired Prometheus rule file, which can be loaded by a Prometheus instance containing Prometheus alerting and recording rules.
- Alertmanager, which defines a desired Alertmanager deployment. The Operator ensures at all times that a deployment matching the resource definition is running.
To learn more about the CRDs introduced by the Prometheus Operator have a look at the design doc.
Prometheus-Operator部署
搜索最新包下载到本地
# 搜索
helm search prometheus-operator
NAME CHART VERSION APP VERSION DESCRIPTION
stable/prometheus-operator 5.0.7 0.29.0 Provides easy monitoring definitions for Kubernetes servi...
# 拉取到本地
helm fetch prometheus-operator
安装
# 安装
helm install -f ./prometheus-operator/values.yaml --name prometheus-operator --namespace=monitoring ./prometheus-operator
# 更新
helm upgrade -f prometheus-operator/values.yaml prometheus-operator ./prometheus-operator
卸载prometheus-operator
# helm delete
helm delete prometheus-operator --purge
# 删除crd
kubectl delete customresourcedefinitions prometheuses.monitoring.coreos.com prometheusrules.monitoring.coreos.com servicemonitors.monitoring.coreos.com
alertmanagers.monitoring.coreos.com
配置operator
config:
global:
resolve_timeout: 5m
smtp_smarthost: 'mail.163.com:25'
smtp_from: 'llussy@163.com'
smtp_auth_username: 'llussy'
smtp_auth_password: 'password'
smtp_require_tls: false
# slack_api_url: '<slack_api_url>'
templates:
- '/etc/alertmanager/config/*.tmpl'
route:
group_by: ['job']
group_wait: 30s
group_interval: 5m
repeat_interval: 5m
receiver: 'default-receiver'
routes:
- receiver: loki-app1
match:
namespace: loki
app: app1
receivers:
- name: 'default-receiver'
email_configs:
- to: '15100499406@163.com'
- name: 'loki-app1'
email_configs:
- to: '297022664@qq.com,1299310393@qq.com'
持久化
storage:
volumeClaimTemplate:
spec:
storageClassName: ceph-rbd
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 5Gi
查看alertmanager配置文件
kubectl -n monitoring get secrets alertmanager-prometheus-operator-alertmanager -o yaml
echo "xxxxx" |base64 -d
查看prometheus配置文件
kubectl get secrets -n monitoring prometheus-prometheus-operator-prometheus -o yaml
# 内容为base64加密的prometheus.yaml.gz
echo "xxxxx" | base64 -d | gunzip
服务发现
测试Service/Pod的metrics时,发现metrics信息并不能被prometheus-operator自动收集到,之前的prometheus没有这个问题。
prometheus-operator没有开启服务发现自动监控时,使用prometheus-operator获取Service/Pod的metrics信息,必须创建相应的ServiceMonitor对象。
(ServiceMonitor是Prometheus Operator中抽象的概念,他的作用就是让配置Prometheus采集Target的配置变化成动态发现的方式,ServiceMonitor通过Deployment对应的Service配置进行挂钩,通过label selector选择Service,并自动发现后端容器。)
一个ServiceMonitor例子 详细信息请点击
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
app: nginx-demo
release: prometheus-operator
name: nginx-demo
namespace: monitoring
#prometheus的namespace
spec:
endpoints:
- interval: 15s
port: http-metrics
namespaceSelector:
matchNames:
- default
#nginx demo的namespace
selector:
matchLabels:
app: nginx-demo
一个一个创建ServiceMonitor对象太过复杂,为解决上面的问题,Prometheus Operator 为我们提供了一个额外的抓取配置的来解决这个问题,我们可以通过添加额外的配置来进行服务发现进行自动监控。我们想要在 Prometheus Operator 当中去自动发现并监控具有prometheus.io/scrape=true这个 annotations 的 Service。需要修改prometheus-operator的配置。
我们的prometheus-operator都是helm安装的,编辑value.yaml文件,修改 additionalScrapeConfigs部分:
抓取service metrics
additionalScrapeConfigs:
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
namespaces:
names:
- kube-system #这里使用ns过滤
- anfeng-ad-k8s-loda
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
抓取pod metrics
- job_name: 'kubernetes-pod'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
抓取etcd metrics
对于 etcd 集群一般情况下,为了安全都会开启 https 证书认证的方式,所以要想让 Prometheus 访问到 etcd 集群的监控数据,就需要提供相应的证书校验。
手工获取
curl --cacert /etc/etcd/ssl/etcd-ca.pem --cert /etc/etcd/ssl/etcd.pem --key /etc/etcd/ssl/etcd-key.pem https://10.21.8.24:2379/metrics
operator抓取
创建secret
kubectl -n monitoring create secret generic etcd-certs --from-file=/etc/etcd/ssl/etcd-ca.pem --from-file=/etc/etcd/ssl/etcd.pem --from-file=/etc/etcd/ssl/etcd-key.pem
修改value.yaml
kubeEtcd:
enabled: true
## If your etcd is not deployed as a pod, specify IPs it can be found on
##
endpoints:
- 10.21.8.24
- 10.21.8.25
- 10.21.8.26
## Etcd service. If using kubeEtcd.endpoints only the port and targetPort are used
##
service:
port: 2379
targetPort: 2379
selector:
component: etcd
## Configure secure access to the etcd cluster by loading a secret into prometheus and
## specifying security configuration below. For example, with a secret named etcd-client-cert
##
serviceMonitor:
scheme: https
insecureSkipVerify: false
#serverName: localhost
caFile: /etc/prometheus/secrets/etcd-certs/etcd-ca.pem
certFile: /etc/prometheus/secrets/etcd-certs/etcd.pem
keyFile: /etc/prometheus/secrets/etcd-certs/etcd-key.pem
抓取k8s集群外metrics
- job_name: 'external-metrics'
static_configs:
- targets: ['10.21.8.105']
metrics_path: '/metrics'
抓取ServiceMonitors
抓取svc的metrics可能和默认配置的有重复,可以使用抓取ServiceMonitors来获取metrics,修改value.yaml的additionalServiceMonitors部分:
# 抓取开启metrics监控的,port名字为k8s-metrics的监控数据。
additionalServiceMonitors:
- name: "k8s-metrics"
namespaceSelector:
any: true
endpoints:
- port: k8s-metrics
path: /metrics
scheme: http
interval: 60s
honorLabels: true
# svc例子
# kubectl get svc -n test-k8s-loda nginx-test-svc -o yaml
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/port: "9527"
prometheus.io/scrape: "true"
labels:
monitor: metrics
name: nginx-test-svc
namespace: test-k8s-loda
spec:
clusterIP: 10.97.140.23
ports:
- name: tcp80
port: 80
protocol: TCP
targetPort: 80
- name: k8s-metrics
port: 9527
protocol: TCP
targetPort: 9527
selector:
app: nginx-test
from: deploy
ns: test-k8s-loda
sessionAffinity: None
type: ClusterIP
status:
loadBalancer: {}
prometheus
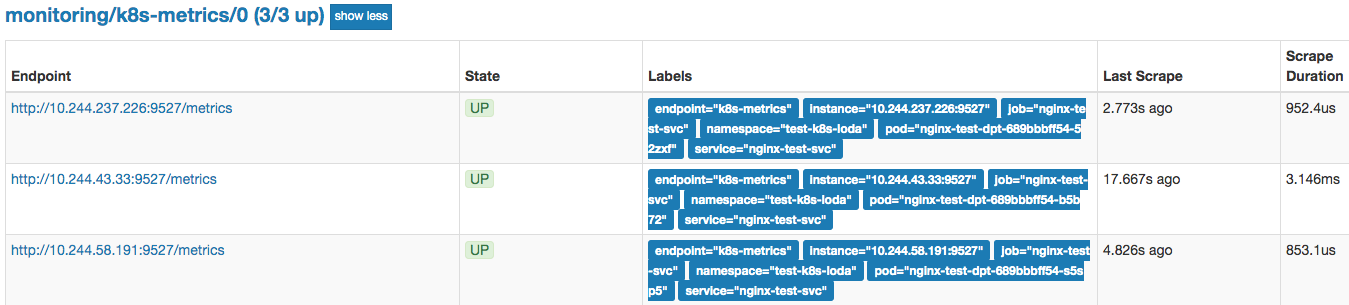
配置prometheus-operator自定义报警
PrometheusRule就是报警规则
查看prometheuses.monitoring.coreos.com的matchLabels部分,保障PrometheusRule labels拥有。
# kubectl -n monitoring get prometheuses.monitoring.coreos.com prometheus-operator-prometheus -o yaml
ruleSelector:
matchLabels:
app: prometheus-operator
release: prometheus-operator
PrometheusRule label可以和alermanager邮件接收部分匹配,不同的报警发给不同的报警人
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: prometheus-operator-0226-lisai-grafana
labels:
app: prometheus-operator
release: prometheus-operator
namespace: monitoring
spec:
groups:
- name: kubernetes-0226-lisai
rules:
- alert: grafana mem
annotations:
message: grafana mem big
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubepersistentvolumeusagecritical
expr: |-
sum(container_memory_usage_bytes{namespace="loki",pod_name=~"loki.*"}) / 1024^3 > 1
for: 1m
labels:
namespace: loki
app: app1
- alert: timetimetime
annotations:
message: time big
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubepersistentvolumeusagecritical
generatorURL: "http://prometheus.test.cloud.idc.com"
expr: |-
sum(container_memory_usage_bytes{namespace="monitoring",pod_name=~"prometheus.*"}) / 1024^3 > 10
for: 1m
labels:
namespace: monitoring
app: app2
- alert: timetimetime
annotations:
message: time big
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubepersistentvolumeusagecritical
generatorURL: "http://prometheus.test.cloud.idc.com"
expr: |-
sum(container_memory_usage_bytes{namespace="monitoring",pod_name=~"prometheus.*"}) / 1024^3 > 10
for: 1m
labels:
namespace: monitoring
app: app2
参考
Prometheus Operator 高级配置 Prometheus Operator 自动发现以及数据持久化
Prometheus Operator 监控 etcd 集群
全手动部署prometheus-operator监控K8S集群以及一些坑